Enrichment in phenotype: WT (6 samples)
- 74 / 136 gene sets are upregulated in phenotype WT
- 1 gene sets are significant at FDR < 25%
- 4 gene sets are significantly enriched at nominal pvalue < 1%
- 9 gene sets are significantly enriched at nominal pvalue < 5%
- Snapshot of enrichment results
- Detailed enrichment results in html format
- Detailed enrichment results in TSV format (tab delimited text)
- Guide to interpret results
Enrichment in phenotype: KO (6 samples)
- 62 / 136 gene sets are upregulated in phenotype KO
- 0 gene sets are significantly enriched at FDR < 25%
- 1 gene sets are significantly enriched at nominal pvalue < 1%
- 4 gene sets are significantly enriched at nominal pvalue < 5%
- Snapshot of enrichment results
- Detailed enrichment results in html format
- Detailed enrichment results in TSV format (tab delimited text)
- Guide to interpret results
Dataset details
- The dataset has 23650 features (genes)
- No probe set => gene symbol collapsing was requested, so all 23650 features were used
Gene set details
- Gene set size filters (min=15, max=500) resulted in filtering out 56 / 192 gene sets
- The remaining 136 gene sets were used in the analysis
- List of gene sets used and their sizes (restricted to features in the specified dataset)
Gene markers for the WT versus KO comparison
- The dataset has 23650 features (genes)
- # of markers for phenotype WT: 11402 (48.2% ) with correlation area 50.1%
- # of markers for phenotype KO: 12248 (51.8% ) with correlation area 49.9%
- Detailed rank ordered gene list for all features in the dataset
- Heat map and gene list correlation profile for all features in the dataset
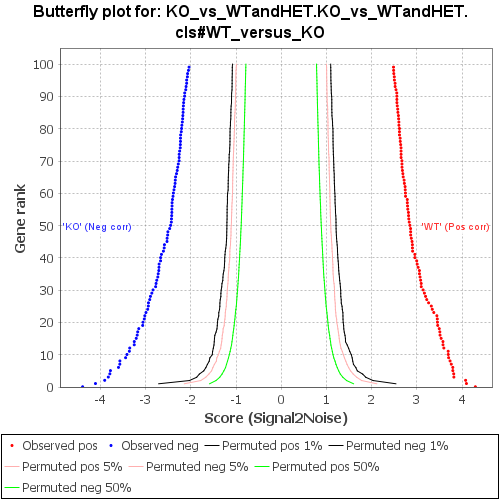
- Butterfly plot of significant genes
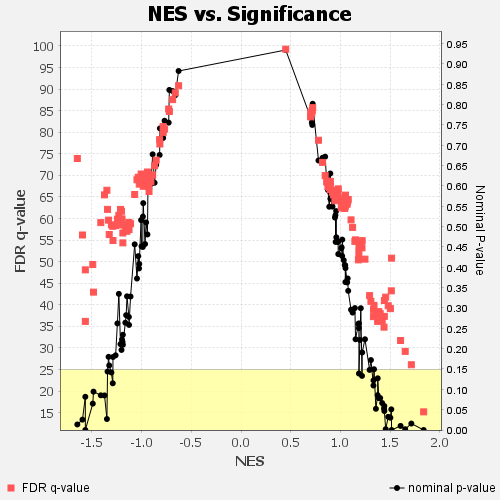
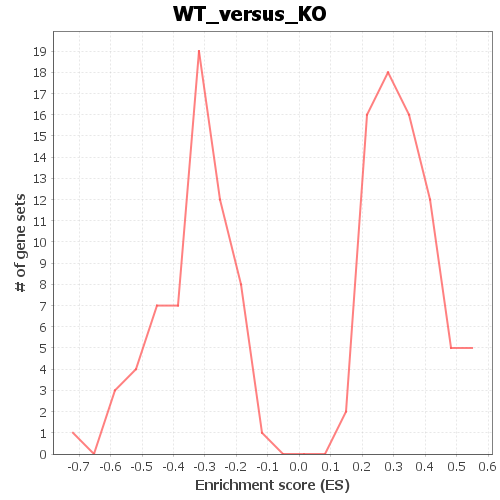
Global statistics and plots
Comments
- Timestamp used as random seed: 1753206385590
- Warning: Phenotype permutation was performed but the number of samples in class A is < 7, phenotype: KO_vs_WTandHET.cls#WT_versus_KO
- Warning: Phenotype permutation was performed but the number of samples in class B is < 7, phenotype: KO_vs_WTandHET.cls#WT_versus_KO
- With small datasets, there might not be enough random permutations of sample labels to generate a sufficient null distribution. In such cases, gene_set randomization might be a better choice.
{kind=link}
{kind=link}
{kind=link}